
728x90
- 비지도 학습 (Unsupervised Learning)
- 비지도 학습이란 정답(Label)이 없는 데이터를 학습하는 방법
- 군집화(clustering)는 비지도 학습의 가장 잘 알려진 방법이다
- 이외에 차원 축소, 생성 모델 등 다양한 방법들이 있다.
- Clustering
- 라벨이 없는 데이터들 내에서 비슷한 특징이나 패턴을 가진 데이터들 끼리 군집화한 후 새로운 데이터가 어떤 군집에 속하는지 추론하는 방법
- 클러스터링의 대표적인 알고리즘은 K-means clustering이 있다.
- K-means Clustering
- K 값이 주어져 있을 때, 주어진 n개의 데이터들을 k개의 클러스터로 묶는 알고리즘
- K는 군집의 수(number of cluster)를 의미하고 means는 평균을 의미한다.
- 데이터의 평균을 활용하여 K개의 군집으로 묶는다는 의미
- K-means
- Initialization : 무작위로 k개의 centeroid를 생성, {c¹, c², ... , cᵏ}
- 특정 조건이 발생할 때까지 다음 2step을 반복
- 사용자가 설정한 반복횟수에 도달 혹은 centeroid가 더 이상 움직이지 않음
- Assignment step : 각 데이터의 cluster membership을 결정

- Refitting step : 각 centeroid를 cluster member의 중심으로 이동

-Example








- Elbow Method
- 군집 수를 결정하는 방법으로 군집 내 총 제곱합(Within Cluster Sum of Squares : WCSS)구하고 적절한 팔꿈치의 위치를 군집 수로 선택하는 방법


- Elbow method의 문제점
- 적당한 k값을 찾는 것이 목표인데 모호한 결과가 나올 수 있다.
- 이를 해결하기 위해 Silhouette Method를 사용한다.

- Silhouette Method란?
- 개별 데이터가 할당된 군집 내 다른 데이터와 얼마나 가깝게 군집화 되어있는지, 그리고 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지 수치로 나타낸 것
- 개별 데이터의 실루엣 계수는 다음과 같이 계산된다.
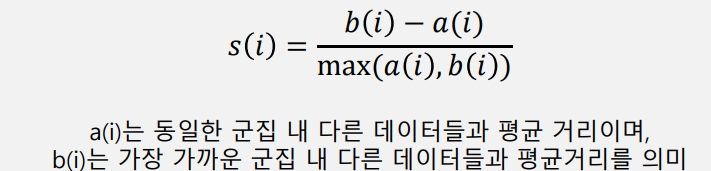
- 실루엣 계수 구하는 방법
- 클러스터링 기법(kmeans)를 통해 10개의 데이터를 3개의 군집으로 나눴다고 가정

- 군집 A의 데이터 i를 선택
- 동일 군집 내 다른 데이터들 간 평균 거리(a(i))를 구한다.

3. 데이터 i와 다른 군집 내 데이터 간 거리 평균을 구한다.
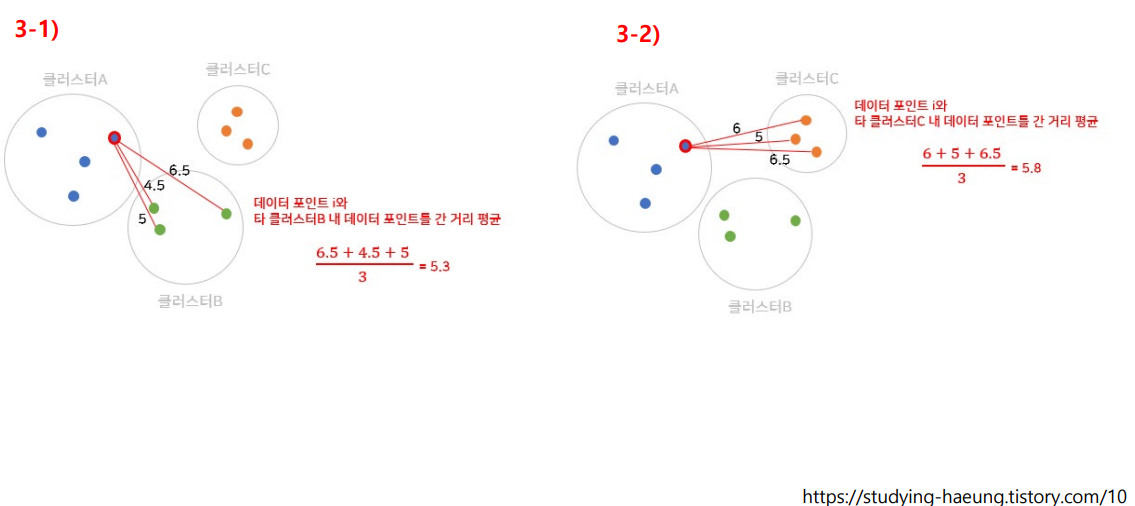
4. (i)와 가장 가까운 군집을 구한다.
5. 4에서 선택된 군집 b(i)와 a(i)간 실루엣 계수를 구한다.
6. 모든 데이터에 대해서 1~5번 과정을 반복하여 실루엣 계수를 구한다.

- 실루엣 계수 평가
- 실루엣 계수는 [-1,+1] 사이의 값을 가질 수 있다.
- 실루엣 계수의 평균값이 1에 가까울 수록 군집화가 잘 된 상태이다.
- S(i)가 0에 가까운 경우, 두 군집 간 거리가 거의 비슷한 경우를 의미
- S(i)가 음수일 경우 데이터 i가 이웃 클러스터에 가까운 경우를 의미 (잘못 할당된 상태)
- 실루엣 분석의 장점
- 클러스터링이 수행된 후 실루엣 계수를 구하기 때문에 클러스터링 알고리즘에 영향을 받지 않음
- 적절한 클러스터 개수를 정할 때 효과적인 방법
- 클러스터링 결과를 시각화 할 수 있다.
- 실루엣 분석의 단점
- 데이터 양이 많을 수록 오래 걸린다.
728x90
'인공지능' 카테고리의 다른 글
| 인공지능(8) - Linear Regression (0) | 2025.03.16 |
|---|---|
| 인공지능(6) - K-Nearest Neighbor (0) | 2025.03.10 |
| 인공지능(5) - HMM : Hidden Markov Model (0) | 2025.02.12 |
| 인공지능(4) - Minimax (0) | 2025.02.11 |
| 인공지능(3) - Fuzzy Logic (0) | 2025.02.10 |