
728x90
- 분류(Classification)란?
- 새로운 데이터가 입력되었을 때, 입력데이터에 대해서 소속을 찾는 것을 분류라고 한다

- 최근접 이웃(Nearest Neighbor)
- 새로 입력된 데이터는 기존에 있는 값들 중에서 가장 비슷한 것(가까운 것 : Nearest Neighbor)으로 분류할 수 있다.

- Euclidean Distance
- 유사한 정도(거리)를 어떻게 구함? => Euclidean Distance
- Euclidean Distance
- N차원의 공간에서 두 점 사이의 거리
- Distance =
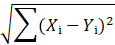
Idea - 새로 입력된 데이터는 기존에 있는 값들 중에서 가장 비슷한 것 (가까운 것 : Nearest Neighbor)으로 분류할 수 있다.
- 문제점
- Noisy Samples 발생
- 서로 다른 종류의 데이터라도 분포가 서로 섞일 수 있음
- 구분하기 어려운 샘플 수집
- Label 실수
- 특수한 사건
- 서로 다른 종류의 데이터라도 분포가 서로 섞일 수 있음
- 최근접 이웃 알고리즘은 Noisy Sample로 인해 성능이 떨어질 수 있다.
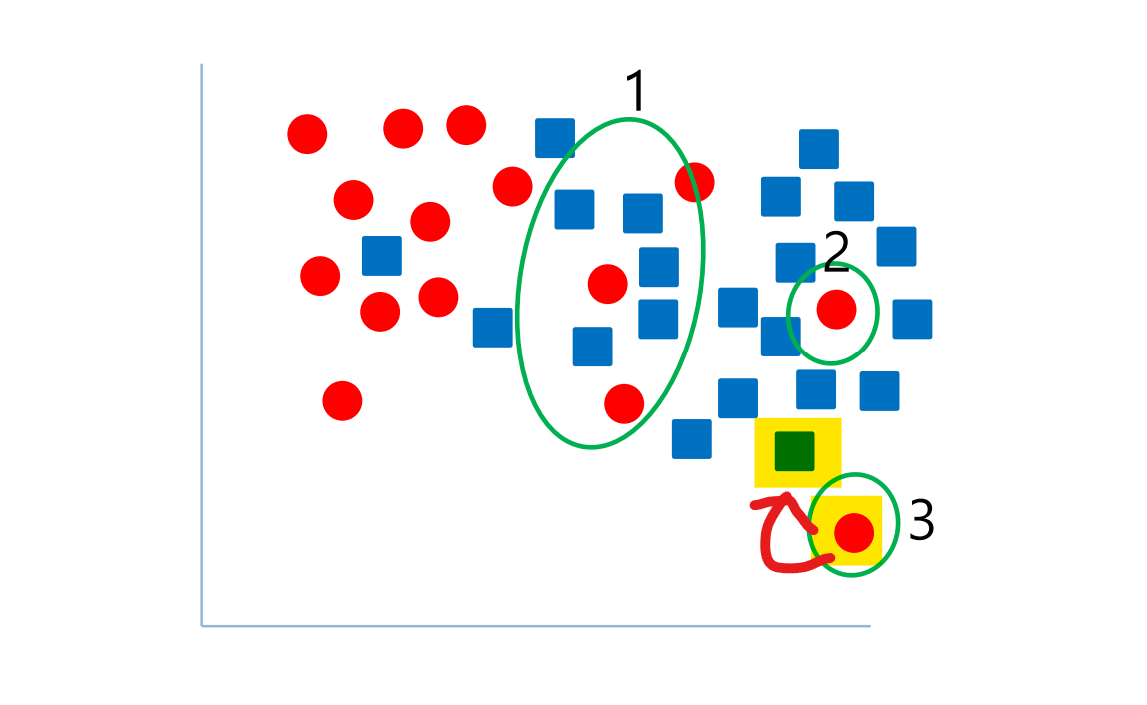
- 해결 방법
- 데이터를 관측
- 거리를 계산 (다른 데이터들 간의 거리를 계산)
- 이웃 찾기 (거리에 따라서 이웃 원들을 정렬)
- 새로운 데이터에 대하여 투표 (가장 가까운 k개의 이웃 중에서 가장 많은 표를 얻은 class로 분류)
- Distance Metrics

- 데이터 정규화 (Data Normalization)
- Data feature의 단위 혹은 스케일이 다를 때, Distance는 단위가 큰 feature에 더 큰 영향을 받는다.
- 문제 해결을 위해 Normalization 이 필요!
- Normalization은 대표적으로 2가지가 있음

- KNN알고리즘은 k 값에 따라 성능이 변한다.
- K가 너무 크면, Underfitting이 발생
- K가 너무 작으면, Overfitting이 발생
- 적당한 K를 찾는게 중요!

- 최적의 K 값 찾기
- Training - Test를 반복하면서 최적의 K를 찾는다.

- Cross Validation
- 교차 검증
- 고정된 Test dataset에 대해 평가를 진행하면 모든 데이터에 잘 동작하는 것인지 Test dataset에 대해서만 잘 동작하는 것인지 알 수 없는 경우가 발생함
- 이를 해결하고자 교차검증 방법이 제안됨
- 데이터를 K개의 subset으로 나누고 Train-test 데이터를 돌아가보면서 K번 테스를 진행

728x90
'인공지능' 카테고리의 다른 글
| 인공지능(8) - Linear Regression (0) | 2025.03.16 |
|---|---|
| 인공지능(7) - K-Means Clustering (0) | 2025.03.10 |
| 인공지능(5) - HMM : Hidden Markov Model (0) | 2025.02.12 |
| 인공지능(4) - Minimax (0) | 2025.02.11 |
| 인공지능(3) - Fuzzy Logic (0) | 2025.02.10 |